(This is joint work with Vaishaal Shankar, Karl Krauth, Qifan Pu, Shivaram Venkataraman, Ion Stoica, Benjamin Recht, and Jonathan Ragan-Kelley)
NumPyWren is about pushing the ideas from PyWren even further, and try and do large-scale linear algebra on serverless-style compute platforms. At first, this seems absurd – high-performance numerical liner algebra code (or “codes”, as the physicsists say) have been dominated by extremely-optimized machines (literal supercomputers) and low-latency IPC mechanisms like MPI for decades. Why is this a good idea?
First, I would argue it arises out of necessity. If Moore’s law really is slowing down, then Baumol’s cost disease suggests that relative to other factors, compute is going to become more expensive. The trend towards disaggregation in the datacenter enables us to begin thinking seriously about decoupling (comparatively expensive compute) from state storage.
Second, many large-scale linear algebra operations such as large-scale linear solves have cubic computation properties but only quadratic communication needs (as you’re only passing around blocks of a matrix). This suggests again that for these workloads, compute may dominate.
Finally, these workloads often exhibit dampened-sinusoid parallelism opportunities.
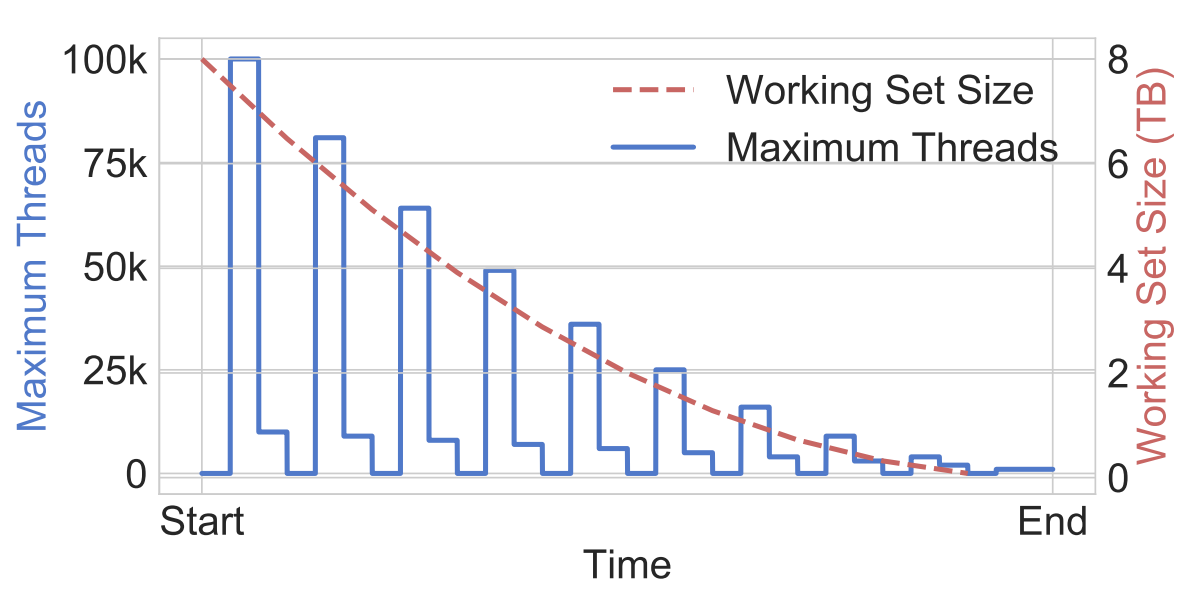
This is theoretical profile of available parallelism and required working set size over time in a distributed Cholesky decomposition. Traditional HPC programming models like MPI couple machine parallelism and memory capacity, and require a static allocation for the lifetime of a process. This is inefficient both due to the changing ratio of parallelism to working set, and the sharp decrease in utilization over time.
Thus, the fine-grained elasticity of serverless platforms actually lets us closely track this workload, enabling performant and efficient utilization of the underlying compute resource:
We’re currently cleaning up the code for a release soon!
Numpywren : Serverless Linear Algebra
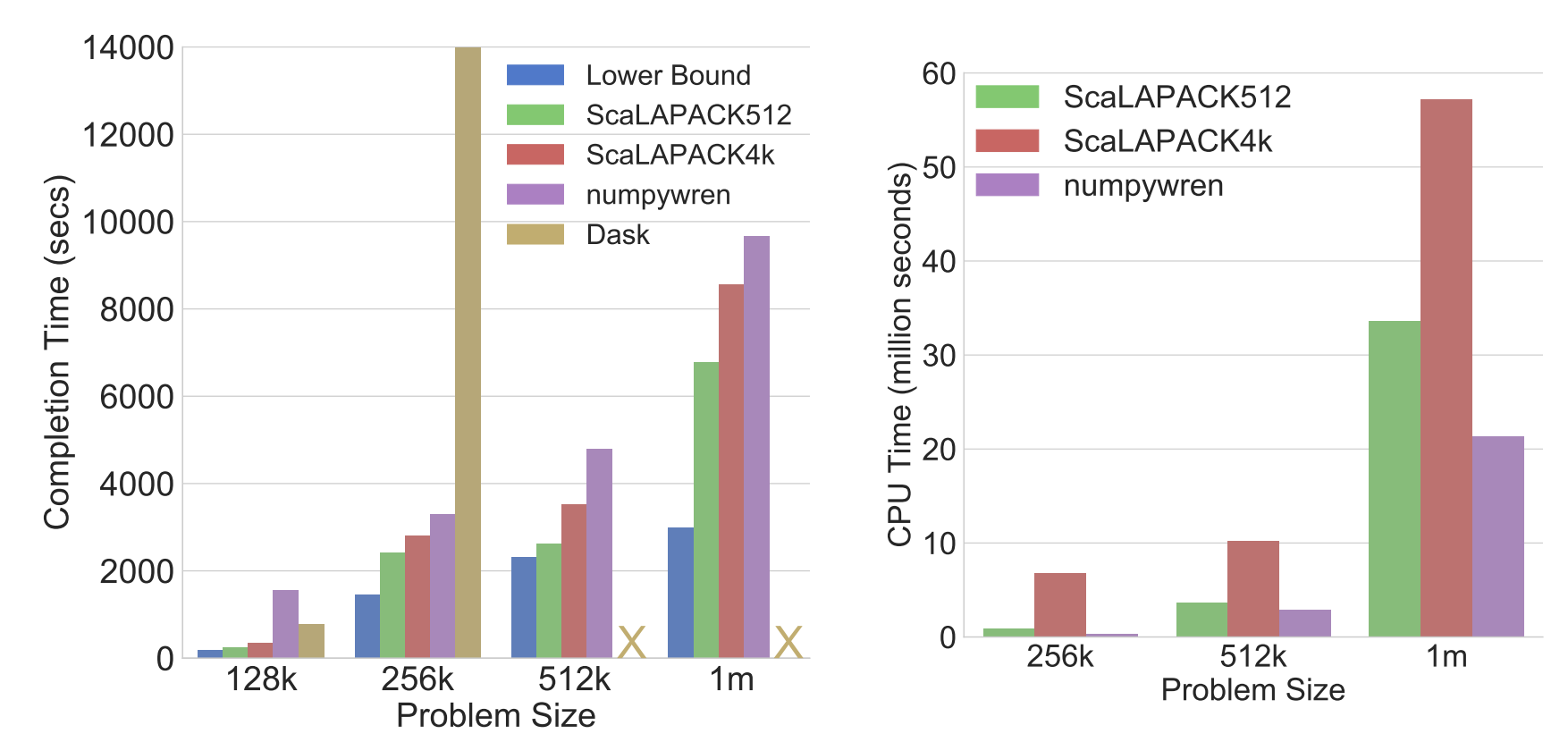
Linear algebra operations are widely used in scientific computing and machine learning applications. However, it is challenging for scientists and data analysts to run linear algebra at scales beyond a single machine. Traditional approaches either require access to supercomputing clusters, or impose configuration and cluster management challenges. In this paper we show how the disaggregation of storage and compute resources in so-called ‘serverless’ environments, combined with compute-intensive workload characteristics, can be exploited to achieve elastic scalability and ease of management. We present numpywren, a system for linear algebra built on a serverless architecture. We also introduce LAmbdaPACK, a domain-specific language designed to implement highly parallel linear algebra algorithms in a serverless setting. We show that, for certain linear algebra algorithms such as matrix multiply, singular value decomposition, and Cholesky decomposition, numpywren’s performance (completion time) is within 33% of ScaLAPACK, and its compute efficiency (total CPU-hours) is up to 240% better due to elasticity, while providing an easier to use interface and better fault tolerance. At the same time, we show that the inability of serverless runtimes to exploit locality across the cores in a machine fundamentally limits their network efficiency, which limits performance on other algorithms such as QR factorization. This highlights how cloud providers could better support these types of computations through small changes in their infrastructure.
