PyWren is a system we built to enable incredibly scalable execution of existing Python functions on the cloud using AWS Lambda (and other “serverless” frameworks). When we say scale, we mean it – you can nearly-instantly run your code on literally thousands of cores with minimal overhead, all billed in 100ms-increments.
PyWren began as a series of exploratory blog posts looking at the compute scaling and IO scaling of Amazon’s cloud services, and blossomed into a joint project between the Berkeley Center for Computational Imaging and the UC Berkely RISE Lab PyWren is a collaborative effort with graduate students Qifan Pu, Shivaram Venkataraman, Vaishaal Shankar.
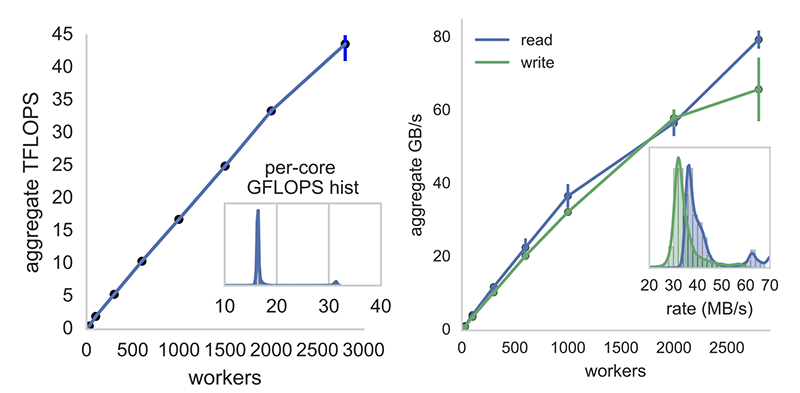
Much of cloud computing infrastructure remains hard to use, in spite of decades of both academic research and commercialization. Fortunately, recent technologies developed for web services and internet startups can be repurposed to enable a much lower-friction scalable cloud experience. Our goal is making the power, elasticity, and dynamism of commercial cloud services like Amazon’s EC2 accessible to busy applied physicists, electrical engineers, and data scientists, as well as a compelling new capability over Matlab, hopefully encouraging migration. We built PyWren, a transparent distributed execution engine on top of AWS Lambda, which simplifies many scale-out use cases for data science and computational imaging. We’ll talk about recent work pushing this infrastructure in unexpected directions, including large-scale linear algebra, sorting, and the viability of other cloud providers.
Press and general interest
- O’Reilly Data Show Podcast (August 2018), Building accessible tools for large-scale computation and machine learning
- The New Stack (February 2017), With PyWren, AWS Lambda Finds Unexpected Market in Scientific Computing
