Extracting 25 TFLOPS from AWS Lambda, or #TheCloudIsTooDamnHard
Recently at the Berkeley Center for Computational Imaging weekly lunch, my wonderful colleague Shivaram Venkataraman from the AMP Lab explained cloud infrastructure to a smart group of physicists, electrical engineers, applied mathematicians and biologists. Even focusing on great technologies like Spark and Dask the conclusion was that #thecloudistoodamnhard. There is a tremendous activation energy in provisioning servers, worrying about piecewise-constant resource pricing and complex storage models, and doing devops work. Professor Ren Ng asked why there was no “cloud button” that one could push and instantly have their current environment up and running on cloud-hosted infrastructure.
And recently, my friend and cofounder @BeauCronin has been tweeting about #TheCloudIWant :
#TheCloudIWant charges me for ~only and exactly~ what I use, and I never have to provision or reserve capacity for any resource.
— Beau Cronin (@beaucronin) October 19, 2016
I think all of this criticism and pining for “something better” is quite correct. While a fraction of my time involves scaling distributed compute to TB datasets across hundreds of machines, a lot of what I do is embarrassingly parallel jobs doing hyperparameter sweeps, Monte Carlo simulations of physical systems, and validation of datasets. I get an algorithm working and then immediately think “I want to test this on 100 input datasets” and then write a for loop and learn to be patient.
There has to be a better way.
Given I sit in the AMP Lab, why not Spark? The spark programming model still requires the provisioning of dedicated servers and currently has poor support for elasticity. Additionally, there are a lot of complications with pyspark that make getting started a challenge. If someone had a robust local cluster, there might be a universe where pyspark would be easy enough to use, but the friction with AWS makes this a challenge.
AWS Lambda
Recent interest in “microservices” has led to various cloud companies offering the ability to execute short-run tasks with minimal overhead. These offerings are still a bit immature and limited. For example, AWS Lambda gives each lambda task:
- a single Nehalem-generation core (exact performance varies a bit)
- 1536 MB of RAM max
- 512 MB of
/tmp/storage - 300s max execution time.
- a runtime that’s either python, node, or Java
This isn’t much, and the runtimes are a limited, although I was curious if it was still enough to do real scientific computing. This is what resulted.
Design Goals:
Additionally, I really wanted to see if there were an easier way to make elastic compute resources available to my non-CS non-devops colleagues. I wanted to make Ren’s “cloud button” more viable. What I really wanted was:
Very little overhead for setup once someone has an AWS account. In particular, no persistent overhead – you don’t have to keep a large (expensive) cluster up and you don’t have to wait 10+ min for a cluster to come up.
As close to zero overhead for users as possible – in particular, anyone who can write python should be able to invoke it through a reasonable interface.
Target jobs that run in the minutes-or-more regime.
I don’t want to run a service. That is, I personally don’t want to offer the front-end for other people to use, rather, I want to directly pay AWS.
It has to be from a cloud player that’s likely to give out an academic grant – AWS, Google, Azure. There are startups in this space that might build cool technology, but often don’t want to be paid in AWS research credits.
PyWren
So I wrote PyWren in my “spare time” (fellow postdocs will get why this is in quotes) to let you do exactly this.
The wrens are mostly small, brownish passerine birds in the mainly New World family Troglodytidae. … Most wrens are small and rather inconspicuous, except for their loud and often complex songs. - Wikipedia
It’s a microservices-Condor, a Wren! (Working with this guy leads to a real focus on ridiculous naming). It’s basically just “map-reduce” minus the “reduce” using AWS Lambda and some awesome python serialization technology originally developed by a now-defunct company called PiCloud that offered a similar service that I loved.
The interface is as close to the Python futures interface
as I could make it. Right now it basically just supports map(func, data_list).
As a trival example, let’s add 1 to the first 10 numbers from our laptop. With PyWren installed locally:
import pywren
import numpy as np
def addone(x):
return x + 1
wrenexec = pywren.default_executor()
xlist = np.arange(10)
futures = wrenexec.map(addone, xlist)
print [f.result() for f in futures]
The output is as expected:
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Behind the scenes, the following has occurred:
- PyWren, running on your laptop (the host), serializes both the function
addone()along with necessary modules, and the data, and sticks both in s3. We call this host submit - PyWren then invokes the lambda function. job start is reached once aws begins calling the lambda function handler.
- The lambda function handler first downloads a full Anaconda python stack, at which point job setup is done.
- The handler invokes the function
fon the serialized dataxfrom within the downloaded python stack. - When that completes, the result is placed in S3, and we have job done.
- On the host, f.result() blocks polling for the existence of the s3 object, and when it is available downloads and unpickles it.
Of course, we can do more computationally-intensive actions, like computing the product of 1600 random matrices with varying standard deviations. My colleague Evan Sparks pointed out that the BLAS operation DGEMM is a great thing to benchmark. So here we’re running BLAS doing a double dense matrix-matrix multiply, and we can measure the total number of FLOPS. (for the remainder we use a
slightly-better instrumented version of the below code).
loopcnt = 10
def big_flops(std_dev):
running_sum = 0
for i in loopcnt:
A = np.random.normal(0, std_dev, (4096, 4096))
B = np.random.normal(0, std_dev, (4096, 4096))
c = np.dot(A, B)
running_sum += np.sum(c)
return running_sum
wrenexec = pywren.default_executor()
std_devs = np.linspace(1, 10, 1600)
futures = wrenexec.map(big_flops, std_devs)
pywren.wait(futures)
Now we can plot and track the results:
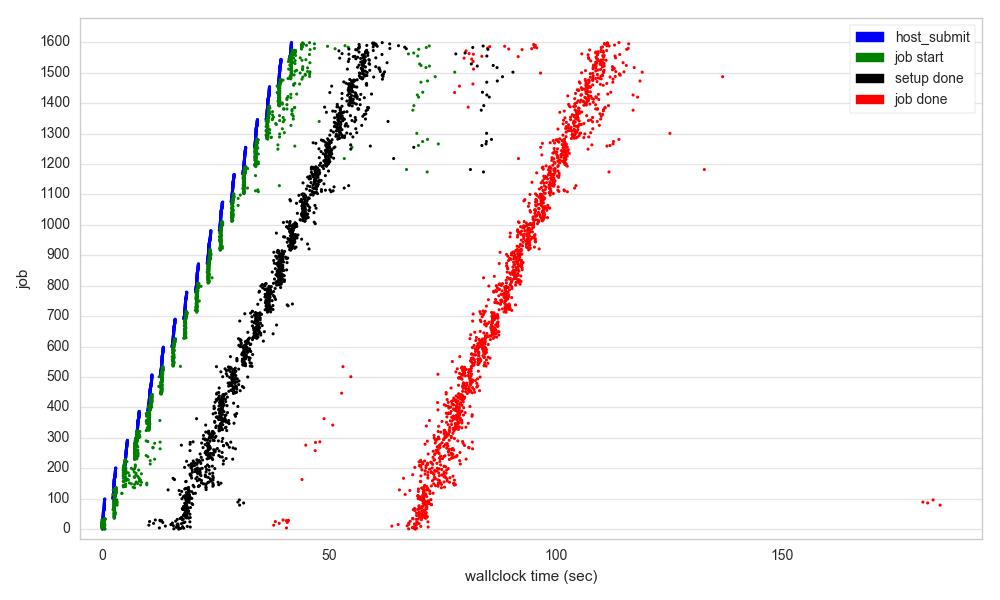 We can mark when each job was submitted by the host (blue dot), when lambda began processing it
(green dot), when the initial setup was done (black dot), and when the job itself
completed (red dot).
We can mark when each job was submitted by the host (blue dot), when lambda began processing it
(green dot), when the initial setup was done (black dot), and when the job itself
completed (red dot).
Interesting things to note:
- The rate of submitting jobs is slow, due to network overhead and possibly may be some rate-limiting going on via the amazon side.
- Most lambda jobs start very quickly after host submission. The variance increases the more active running jobs there are, though.
- Setup can take a while – for this short job, it’s ~20% of the execution time, although the jobs themselves take on average ~75 seconds (less than the 300s max), so there is room to reduce this overhead percentage.
- Some jobs finish incredibly quickly, suggesting they are running on faster / less-contested hardware.
- There are some real stragglers – note the cluster of jobs finishing around 180s.
We can then compute the effective total throughput
as a function of time (blue line): including overhead, how many GFLOPS
did this task run at? We can also compute the total peak
GFLOPS in flight (green) – how many simultaneous GFLOPS are being computed at this
moment, across the entire job pool.
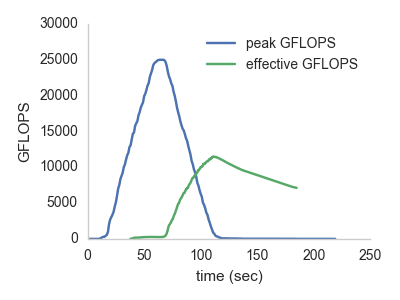
Note the effective flops rises quickly once jobs start returning, and then declines slowly as we wait for the stragglers. The blue line peaks when the maximum number of simultaneous lambda workers is crunching on threads, which peaks at over 25 TFLOPS! This feels amazing for a bunch of plain-old python processes.
Limitations
Anti-goals:
- I don’t want to support inter-task computation or IPC. I just want a
mapthat works as transparently as possible. - We are not optimizing for tasks with duration < 20s. Overhead is non-trivial
This isn’t a generic compute platform yet – in addition to the
limitations on invidiual lambda processes listed above, marshalling
the python code intelligently isn’t totally debugged, and the
small space in /tmp means we’re limited in how much of the
pydata stack we can install on the worker.
But I am making a bet that the limitations on this sort of worker will improve in the near future. To pull this off, I had to e-mail AWS and request an increase in simultaneous lambda workers to 2000, which they quickly did. The ideal case is of course a lambda-like service that runs arbitrary containers quickly with fixed resource budgets,
The future
We can make cloud compute easier for scientific computing users. We can bring the power of elasticity to the masses. While fun, there aren’t hard systems challenges here, it’s just about polishing things well enough to compel regular users. Indeed, this is a place a few startups have tried to succeed in, although it’s most likely not viable as a stand-alone business model. More and more people are starting to try and do real work with microservices. My friend and colleague Keith Winstein , for example, has been doing amazing research in this space for video codecs, and was instrumental in helping me understand the early limitations of Lambda.
So try PyWren
out, look in the examples directory, and if you’re the sort of
person who wants to run a lot of small-ish jobs in parallel let me
know!
Special thanks to Ren Ng for the original motivitation to actually implement this, the PiCloud founders back in 2008 for offering a near-identical service back when it was hard, Shivaram Venkataraman and Evan Sparks for help in early implementation and real guidance, and Keith Winstein for showing me it was possible to run 1000+ lambda instances simultaneously, and as always, Ben Recht for letting me fool around like this instead of writing papers.
